inlineintread() { int x=0,f=1; char c=getchar(); while (c<'0' || c>'9') { if (c=='-') f=-1; c=getchar(); } while (c>='0' && c<='9') { x=x*10+c-'0'; c=getchar(); } return x*f; }
inlinevoidprint(int x) { if (x<0) { putchar('-');x=-x; } if (x>9) print(x/10); putchar(x%10+'0'); }
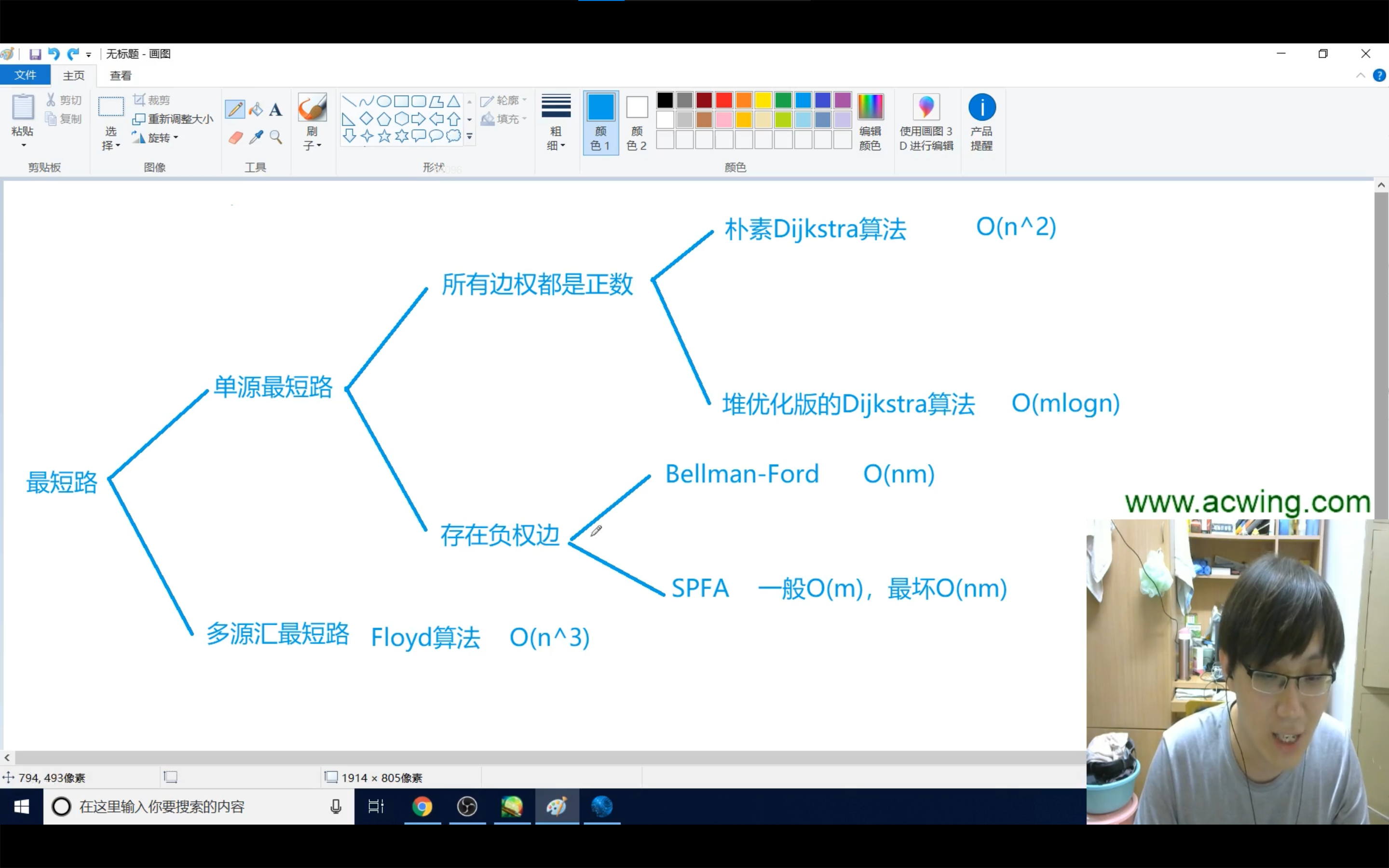
1 基础算法
1.1 排序
1.1.1 快速排序
1 2 3 4 5 6 7 8 9 10 11
voidquick_sort(int q[], int l, int r){ if (l >= r) return; int x = q[(l + r) / 2], i = l - 1, j = r + 1; while (i < j) { while (q[++ i] < x); while (q[-- j] > x); if (i < j) swap(q[i], q[j]); } quick_sort(q, l, j); quick_sort(q, j + 1, r); }
1.1.2 快速选择
选择数组里第k小数
1 2 3 4 5 6 7 8 9 10 11 12 13
intquick_sort(int l, int r, int k){ if (l == r) return a[l]; int x = a[(l + r) >> 1], i = l - 1, j = r + 1; while (i < j) { while (a[ ++ i] < x); while (a[ -- j] > x); if (i < j) swap(a[i], a[j]); } int sl = j - l + 1; if (sl >= k) returnquick_sort(l, j, k); returnquick_sort(j + 1, r, k - sl);
}
1.1.2 归并排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14
voidmerge_sort(int q[], int l, int r){ if (l >= r) return; int mid = l + r >> 1; merge_sort(q, l, mid),merge_sort(q, mid + 1, r);
int i = l, j = mid + 1, k = 0; while (i <= mid && j <= r) tmp[k ++] = q[i] <= q[j] ? q[i ++] : q[j ++];
while (i <= mid) tmp[k ++] = q[i ++]; while (j <= r) tmp[k ++] = q[j ++];
for (i = l, j = 0; i <= r; i ++, j ++) q[i] = tmp[j]; }
1.2 查找
1.2.1 二分查找
x的左边界
1 2 3 4 5 6
int l = 0, r = n - 1; while (l < r) { int mid = l + r >> 1; if (q[mid] >= x) r = mid; else l = mid + 1; }
x的右边界
1 2 3 4 5 6 7
int l = 0, r = n - 1; while (l < r) { int mid = l + r + 1 >> 1; if (q[mid] <= x) l = mid; else r = mid - 1; } cout << l << endl;
1.3 高精度
1.3.1 高精度加法
1 2 3 4 5 6 7 8 9 10 11 12 13
//C = A + B vector<int> add(vector<int> &A, vector<int> &B){ vector<int> C; int t = 0; for (int i = 0; i < A.size() || i < B.size(); i ++) { if (i < A.size()) t += A[i]; if (i < B.size()) t += B[i]; C.push_back(t % 10); t /= 10; } if (t) C.push_back(t); return C; }
//(bool) A >= B boolcmp(vector<int> &A, vector<int> &B){ if (A.size() != B.size()) return A.size() > B.size(); for (int i = A.size() - 1; i >= 0; i --) if (A[i] != B[i]) return A[i] > B[i];
returntrue; } //C = A - B vector<int> sub(vector<int> &A, vector<int> &B) if(!cmp(A, B))returnsub(B, A); vector<int> C; for (int i = 0, t = 0; i < A.size(); i ++ ) { t = A[i] - t; if (i < B.size()) t -= B[i]; C.push_back((t + 10) % 10); if (t < 0) t = 1; else t = 0; }
vector<int> mul(vector<int> &A, int b){ vector<int> C; int t = 0; for (int i = 0; i < A.size() || t; i ++) { if (i < A.size()) t += A[i] * b; C.push_back(t % 10); t /= 10; } while (C.size() > 1 && C.back() == 0) C.pop_back(); return C; }
1.3.4 高精度除法
1 2 3 4 5 6 7 8 9 10 11 12 13
//C = 商, r = 余 vector<int> div(vector<int> &A, int b, int &r){ vector<int> C; r = 0; for (int i = A.size() - 1; i >= 0; i --) { r = r * 10 + A[i]; C.push_back(r / b); r %= b; } reverse(C.begin(), C.end()); while (C.size() > 1 && C.back() == 0) C.pop_back(); return C; }
1.4 前缀和差分
1.4.1 一维前缀和
含义: s[i] = a[1] + a[2] + … + a[i]
1 2
for (int i = 1; i <= n; i ++) scanf("%d", &a[i]); for (int i = 1; i <= n; i ++) s[i] = s[i - 1] + a[i];
for (int i = 1; i <= n; i++) for (int j = 1; j <= m; j ++) scanf("%d", &a[i][j]);
for (int i = 1; i <= n; i ++) for (int j = 1; j <= m; j ++) s[i][j] = s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1] + a[i][j];
1.4.3 一维差分
1 2 3 4 5 6
int a[N], b[N];
voidinsert(int l, int r, int x){ b[l] += x; b[r + 1] -= x; }
1.4.4 二维差分
1 2 3 4 5 6 7 8
int a[N][N], b[N][N];
voidinsert(int x1, int y1, int x2, int y2, int x){ b[x1][y1] += x; b[x2 + 1][y1] -= x; b[x1][y2 + 1] -= x; b[x2 + 1][y2 + 1] += x; }
1.5 双指针算法
核心:将O(n^2)的算法, 利用双指针能降为O(n)
思路:先写一个暴力做法, 看一下i和j有没有单调规律
1.5.1 模板1
1 2 3 4 5 6 7 8
for (int i = 0, j = 0; i < n; i ++) { //加入i s[a[i]] ++; //s[],计数器 //假如不满足, 右移j直到满足 while (check()) j ++; //记录答案 ans = max(ans, j - i + 1); }
1.6 位运算
1.6.1 求n的二进制表示中第k位
1
(n >>) k & 1
1.6.2 x的最后一位1
1 2 3
intlowbit(int x){ return x & -x; // x & (~x + 1) }
1.7 离散化
大范围内少数量的数, 映射到从0开始的一段连续的值(下标);
可能存在重复元素 (去重)
如何算出x离散化后的值 (二分)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
typedef pair<int, int> PII; constint N = 300010; int n, m; int a[N], s[N]; vector<int> alls; vector<PII> add, query;
intfind(int x){ int l = 0, r = alls.size() -1 ; while (l < r) { int mid = (l + r) >> 1; if (alls[mid] >= x) r = mid; else l = mid + 1; } return r + 1; }
int st = -2e9, ed = -2e9; for (auto seg : segs) if (ed < seg.first) { if (st != -2e9) res.push_back({st, ed}); st = seg.first, ed = seg.second; } else ed = max(ed, seg.second);
int hh = 0, tt = -1; for (int i = 0; i < n; i ++) { if (hh <= tt && q[hh] < i - k + 1) hh ++; //单调递增 while (hh <= tt && a[q[tt]] >= a[i]) tt--; q[++ tt] = i; if (i >= k - 1) printf("%d ", a[q[hh]]); }
constint N = 20010; int n; int s[N][26], cnt[N], idx;
//插入 voidinsert(string str){ int p = 0; for (int i = 0; str[i]; i++) { int u = str[i] - 'a'; if (!s[p][u]) s[p][u] = ++idx; p = s[p][u]; } cnt[p] ++; }
//查询 intquery(string str){ int p = 0; for (int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if (!s[p][u]) return0; p = s[p][u]; } return cnt[p]; }
//0-1 Trie 插入x voidinsert(int x){ int p = 0; for (int i = 31; i >= 0; i --) { int u = (x >> i) & 1; if (!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } }
//查询最大异或值 intquery(int x){ int p = 0, ret = 0; for (int i = 31; i >= 0; i --) { int u = (x >> i) & 1; ret <<= 1; if (son[p][!u]) ret += 1, p = son[p][!u]; else p = son[p][u]; } return ret; }
//down voiddown(int u){ int t = u; if (2 * u <= len && h[2 * u] < h[t]) t = 2 * u; if (2 * u + 1 <= len && h[2 * u + 1] < h[t]) t = 2 * u + 1; if (u != t) { swap(h[u], h[t]); down(t); } }
//up voidup(int u){ int t = u; while (u / 2 && h[u / 2] > h[u]) { swap(h[u / 2], h[u]); u /= 2; } }
constint N = 100010; int n; int h[N], hp[N], ph[N], len; //ph:第i个插入的数在堆的哪个位置 //hp: 堆的第i个位置是第几个插入的数
voidheap_swap(int a, int b){ swap(ph[hp[a]], ph[hp[b]]); swap(hp[a], hp[b]); swap(h[a], h[b]); }
voiddown(int u){ int t = u; if (2 * u <= len && h[2 * u] < h[t]) t = 2 * u; if (2 * u + 1 <= len && h[2 * u + 1] < h[t]) t = 2 * u + 1; if (u != t) { heap_swap(u, t); down(t); } }
voidup(int u){ while (u > 1 && h[u / 2] > h[u]) { heap_swap(u / 2, u); u /= 2; } }
3 哈希表
3.1 模拟散列表
3.1.1 拉链法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
constint N = 100003; int n; int h[N], e[N], ne[N], idx;
voidinsert(int x){ int k = (x % N + N) % N; e[idx] = x; ne[idx] = h[k]; h[k] = idx ++; }
boolfind(int x){ int k = (x % N + N) % N; for (int i = h[k]; i != -1; i = ne[i]) if (e[i] == x) returntrue;
returnfalse; }
3.1.2 开放式寻址法
1 2 3 4 5 6 7 8 9 10 11 12 13 14
constint N = 200003, null = 0x3f3f3f3f; int n; int h[N];
intfind(int x){ int k = (x % N + N) % N; while (h[k] != null && h[k] != x) { k ++; if (k == N) { k = 0; } } return k; }
3.2 字符串哈希 (字符串前缀哈希法)
原理:将一个字符串看成一个P进制的数,将P进制数转换成十进制数,得到该字符串的哈希值。
例字:ABCD: A * P^3 + B * P^2 + C * P^1 + D * P^0所得的十进制数就是该字符串的哈希值。
intf(string state){ int res = 0; for (int i = 0; i < state.size(); i ++) { if (state[i] != 'x') { int t = state[i] - '1'; res += abs(i / 3 - t / 3) + abs(i % 3 - t % 3); } } return res; }
while (q.size()) { auto t = q.top(); q.pop(); string state = t.second; if (state == end) break;
if (st[state]) continue; st[state] = true;
int step = dist[state]; int x, y; for (int i = 0; i < state.size(); i ++) { if (state[i] == 'x') { x = i / 3, y = i % 3; } } string source = state; for (int i = 0; i < 4; i ++) { int tx = x + dx[i]; int ty = y + dy[i]; if (tx >= 0 && tx < 3 && ty >= 0 && ty < 3) { swap(state[x * 3 + y], state[tx * 3 + ty]); if (!dist[state] || dist[state] > step + 1) { dist[state] = step + 1; prev[state] = {source, op[i]}; q.push({f(state) + dist[state], state}); } swap(state[x * 3 + y], state[tx * 3 + ty]); } } } string res; while (end != start) { res += prev[end].second; end = prev[end].first; } reverse(res.begin(), res.end()); return res; }
intmain(){ string g, c, seq; while (cin >> c) { g += c; if (c != "x") seq += c; } int t = 0; for (int i = 0; i < seq.size(); i ++) for (int j = i + 1; j < seq.size(); j ++) if (seq[i] > seq[j]) ++t; if (t & 1) puts("unsolvable"); else cout << bfs(g) << endl;
intf(){ int res = 0; for (int i = 0; i < st.size(); i ++) if (st[i] != 'x') { int t = st[i] - '1'; res += abs(i / 3 - t / 3) + abs(i % 3 - t % 3); } return res; } booldfs(int u){ if (f() + u > depth) returnfalse; if (st == ed) returntrue;
int x, y; for (int i = 0; i < st.size(); i ++) if (st[i] == 'x') x = i / 3, y = i % 3;
for (int i = 0; i < 4; i ++) { int a = x + dx[i], b = y + dy[i]; if (u && path[u - 1] + i == 3) continue; if (a >= 0 && a < 3 && b >= 0 && b < 3) { swap(st[x * 3 + y], st[a * 3 + b]); path[u] = i; if (dfs(u + 1)) returntrue; swap(st[x * 3 + y], st[a * 3 + b]); } } returnfalse; } voidsolve(){ for (depth = 0;; ++depth) if (dfs(0)) break; for (int i = 0; i < depth; i ++) cout << op[path[i]]; } intmain(){ char c; while (cin >> c) { st += c; }
int t = 0; for (int i = 0; i < st.size(); i++) for (int j = i + 1; j < st.size(); j ++) if (st[i] != 'x' && st[j] != 'x' && st[i] > st[j]) ++t; if (t & 1) cout << "unsolvable" << endl; elsesolve(); return0; }
constint N = 100; int n, path[N]; string st, ed; int mp[10];
char op[] = "dlru"; int dx[] = {1, 0, 0, -1}, dy[] = {0, -1, 1, 0}; int depth; // distance intf(){ int dist = 0; for (int i = 0; i < st.size(); i ++) if (st[i] != 'X') { int a = i / 3, b = i % 3; int x = mp[st[i] - '0'] / 3, y = mp[st[i] - '0'] % 3; dist += abs(a - x) + abs(b - y); } return dist; } // ida* booldfs(int u){ if (u + f() > depth) returnfalse; if (st == ed) returntrue; // find X int x, y; for (int i = 0; i < st.size(); i ++) if (st[i] == 'X') x = i / 3, y = i % 3; // try for (int i = 0; i < 4; ++ i) { int a = x + dx[i], b = y + dy[i]; // 去抖动 if (u && path[u - 1] + i == 3) continue; // 回溯 if (a >= 0 && a < 3 && b >= 0 && b < 3) { swap(st[x * 3 + y], st[a * 3 + b]); path[u] = i; if (dfs(u + 1)) returntrue; swap(st[x * 3 + y], st[a * 3 + b]); } } returnfalse; } voidsolve(){ // mp for (int i = 0; i < ed.size(); ++ i) if (ed[i] != 'X') mp[ed[i] - '0'] = i; // ida* for (depth = 0;; ++ depth) if (dfs(0)) break; // output ans cout << depth << endl; for (int i = 0; i < depth; ++i) { cout << op[path[i]]; } cout << endl; }
intmain(){ ios::sync_with_stdio(false);cin.tie(0);cout.tie(0); cin >> n; for (int i = 1; i <= n; i ++) { cin >> st >> ed; cout << "Case "<< i << ": "; solve(); } return0; }
3.3 树与图的DFS
3.3.1 领接表
1 2 3 4 5 6 7 8 9
constint N = 100010, M = N * 2;
int h[N], e[M], ne[M], idx;
//领接表加边a->b voidadd(int a, int b){ e[idx] = b, ne[idx] = h[a], h[a] = idx ++; }
1 2 3 4 5
int h[N], w[N], e[N], ne[N], idx; //add,a->b ,权重c voidadd(int a, int b, int c){ e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++; }
3.3.2 深度优先遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int h[N], e[M], ne[M], idx; int vis[N];
//树的dfs voiddfs(int u) { vis[u] = true;
for (int i = h[u]; i != -1; i = ne[i]) { if (!vis[e[i] ]) { dfs(e[i]) } } }
int res = 0; for (int i = 0; i < n; i ++) { int t = -1; for (int j = 1; j <= n; j ++) if (!st[j] && (t == -1 || dist[t] > dist[j])) t = j; //不是第一个点且距离是正无穷, 说明与集合没有边相连 if (i && dist[t] == INF) return INF; // 第一个点时, 不用加权重 if (i) res += dist[t];
for (int j = 1; j <= n; j ++) if (!st[j] && dist[j] > g[t][j]) dist[j] = g[t][j];
constint N = 100010, M = 200010, INF = 0x3f3f3f3f;
int n, m; TIII g[M]; int p[N];
intfind(int x){ return p[x] == x ? x : p[x] = find(p[x]); }
intkruskal() { sort(g, g + m); //初始化并查集 for (int i = 1; i <= n; i ++) p[i] = i;
int res = 0; //最小生成树 int num = n; //集合数量 for (int i = 0; i < m; i ++) { auto [c, a, b] = g[i]; a = find(a), b = find(b); //如果a,b不连通, 连通a,b if (a != b) { p[a] = b; res += c; num --; } }
int n, m; int h[N], e[M], ne[M], idx; int color[N];
voidadd(int a, int b) { e[idx] = b, ne[idx] = h[a], h[a] = idx ++; }
booldfs(int u, int c) { color[u] = c; for (int i = h[u]; i != -1; i = ne[i]) { int j = e[i]; if (!color[j]) { if (!dfs(j, 3 - c)) returnfalse; } if (color[j] == c) returnfalse; } returntrue; }
boolisb() { for (int i = 1; i <= n; i ++) if (!color[i]) if (!dfs(i, 1)) returnfalse; returntrue; }
voiddivised(int n) { for (int i = 2; i <= n / i; i ++) { if (n % i == 0) {
int s = 0; while (n % i == 0) { n /= i; s ++; } printf("%d %d\n", i, s); } }
if (n > 1) printf("%d %d\n", n, 1); puts(""); }
4.1.3 质数筛
埃氏筛法 O(nloglogn)
欧拉筛 O(n)
埃氏筛法
对于每个质数, 都把以它为质因子的数筛去
1 2 3 4 5 6 7 8 9 10 11 12 13 14
constint N = 1000010; int prime[N], cnt; bool st[N];
voidget_primes(int n) { for (int i = 2; i <= n; i ++) if (!st[i]) { prime[cnt ++] = i; for (int j = i + i; j <= n; j += i) st[j] = true; } }
欧拉筛
ps : pj 是 i 的最小质因子时, pj 也是 pj * i 的最小质因子!
根据这个条件就能保证每个合数只被最小质因子筛一次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
constint N = 1000010; int prime[N], cnt; bool st[N];
voidget_primes(int n) { for (int i = 2; i <= n; i ++) { if (!st[i]) prime[cnt ++] = i; for (int j = 0; prime[j] <= n / i; j ++) { st[prime[j] * i] = true; if (i % prime[j] == 0) break; // 重 } } }
4.2 约数
4.2.1 试除法-求一个数的约数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
vector<int> get_divisors(int n) { vector<int> res; for (int i = 1; i <= n / i; i ++) { if (n % i == 0) { res.push_back(i); if (i != n / i) res.push_back(n / i); } }
inteuler_phi(int n){ int res = n; for (int i = 2; i <= n / i; i ++) if (n % i == 0) { while (n % i == 0) n /= i; res = res - (res / i); } if (n > 1) res = res - (res / n); return res; }
intmain(){ cin >> n >> m; for (int i = 1; i <= n; i ++) { int v, w; cin >> v >> w; for (int j = m; j >= v; j --) f[j] = max(f[j], f[j - v] + w); } cout << f[m]; return0; }
intmain(){ cin >> n >> m; for (int i = 1; i <= n; i ++) { int v, w; cin >> v >> w; for (int j = 1; j <= m; j ++) { f[i][j] = f[i - 1][j]; for (int k = 1; k * v <= j; k ++) f[i][j] = max(f[i][j], f[i - 1][j - v * k] + w * k); } } cout << f[n][m]; return0; }
intmain(){ cin >> n >> m; for (int i = 1; i <= n; i ++) { int v, w; cin >> v >> w; for (int j = 1; j <= m; j ++) { if (j >= v) f[j] = max(f[j], f[j - v] + w); } } cout << f[m]; return0; }
intmain(){ cin >> n >> m; for (int i = 1; i <= n; i ++) { int v, w; cin >> v >> w; for (int j = v; j <= m; j ++) f[j] = max(f[j], f[j - v] + w); }
cout << f[m]; return0; }
5.3 多重背包
有 N种物品和一个容量是 V 的背包。第 i 种物品最多可选择Si件,每件体积是 vi,价值是 wi。求使物品体积总和不超过背包容量的最大价值。
01背包思路
第i种物品最多有si件,可以看成01背包中的si件相同的物品,这样即可套用01背包的思路和代码来解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
constint N = 110; int n, m; int f[N];
intmain(){ cin >> n >> m; while (n --) { int v, w, s; cin >> v >> w >> s; for (int i = 1; i <= s; i ++) for (int j = m; j >= v; j --) f[j] = max(f[j], f[j - v] + w); }
cout << f[m]; return0; }
完全背包思路
可以将多重背包当成完全背包来推,只是每个i物品的数量k有限制。
集合表示:
f[i][j]: 前i个物品(每个可以无限选),总体积不超过j的所有集合。
max:f[i][j]的所有集合中的中求最大价值的
状态转移:
f[i][j] = f[i - 1][j]:不选当前物品i
f[i][j] = max(f[i - 1][j], f[i - 1][j - v[i]*k] + w[i] * k)j >= v[i] * k && k <= s :选当前物品i,且总体积不超过j,数量不超过s的最大价值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
constint N = 110; int f[N][N]; int n, m;
intmain() { cin >> n >> m; for (int i = 1; i <= n; i ++) { int v, w, s; cin >> v >> w >> s; for (int j = 1; j <= m; j ++) { for (int k = 0; k * v <= j && k <= s; k ++) f[i][j] = max(f[i][j], f[i - 1][j - v * k] + w * k); } }
cout << f[n][m]; return0; }
一维数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
constint N = 20010; int n, m; int f[N];
intmain(){ cin >> n >> m; for (int i = 0; i < n; i ++) { int v, w, s; cin >> v >> w >> s; for (int j = m; j >= 0; j --) for (int k = 1; k <= s && v * k <= j; k ++) f[j] = max(f[j], f[j - v * k] + w * k); } cout << f[m]; return0; }
constint N = 15000, M = 2010; int n, m; int v[N], w[N]; int f[M];
intmain() { cin >> n >> m; int cnt = 0; while (n --) { int a, b, s; cin >> a >> b >> s; int k = 1; while (k <= s) { cnt ++; v[cnt] = a * k; w[cnt] = b * k; s -= k; k <<= 1; } if (s > 0) { cnt ++; v[cnt] = a * s; w[cnt] = b * s; } } for (int i = 1; i <= cnt; i ++) for (int j = m; j >= v[i]; j --) f[j] = max(f[j], f[j - v[i]] + w[i]);
intmain(){ cin >> n >> m; for (int i = 1; i <= n; i ++) { int v, w, s; cin >> v >> w >> s; int k = 1; while (k <= s) { for (int j = m; j >= v * k; j --) f[j] = max(f[j], f[j - v * k] + w * k); s -= k; k <<= 1; } if (s) for (int j = m; j >= v * s; j --) f[j] = max(f[j], f[j - v * s] + w * s); } cout << f[m]; return0; }
单调队列优化
完全背包:求所有前缀的最大值
多重背包:求前一个区间的最大值
当计算f[i][j]时,由 f[i][j] = max(f[i][j], f[i - 1][j - v * s] + w * s)展开,可得如下:
constint N = 110; int n, m; int v[N][N], w[N][N], s[N]; int f[N];
intmain() { cin >> n >> m; for (int i = 1; i <= n; i ++) { cin >> s[i]; for (int j = 1; j <= s[i]; j ++) { cin >> v[i][j] >> w[i][j]; } }
for (int i = 1; i <= n; i ++) for (int j = m; j >= 0; j --) for (int k = 1; k <= s[i]; k ++) if (j >= v[i][k]) f[j] = max(f[j], f[j - v[i][k]] + w[i][k]);
q[0] = -2e9; int len = 0; for (int i = 0; i < n; i ++) { int l = 0, r = len; while (l < r) { int mid = l + (r - l + 1) / 2; if (q[mid] < a[i]) l = mid; else r = mid - 1; }
/* f[i][j] = min(f[i][k] + f[k + 1][j] + s[j] - s[i - 1]); */ intmain() { int n; scanf("%d", &n); for (int i = 1; i <= n; i ++) scanf("%d", &s[i]);
for (int i = 1; i <= n; i ++) s[i] += s[i - 1];
for (int len = 2; len <= n; len ++) for (int i = 1; i + len - 1 <= n; i ++) { int l = i, r = i + len - 1; f[l][r] = 1e9; for (int k = l; k < r; k ++) f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r] + s[r] - s[l - 1]); }
intget(vector<int> &v, int l, int r){ int res = 0; for (int i = r; i >= l; i --) res = res * 10 + v[i]; return res; }
intpower10(int i){ int res = 1; while (i --) res *= 10; return res; } intcount(int n, int x) { if (!n) return0;
vector<int> v; for (; n; n /= 10) v.push_back(n % 10);
n = v.size(); int res = 0; for (int i = n - 1 - !x; i >= 0; i --) { if (i < n - 1) { res += get(v, i + 1, n - 1) * power10(i); if (!x) res -= power10(i); } // cout <<"--" << res << endl; if (v[i] == x) res += get(v, 0, i - 1) + 1; elseif (v[i] > x) res += power10(i); // cout << "--" << res << endl; } return res; }
intmain() { int a, b; while (cin >> a >> b, a || b) { if (a > b) swap(a, b); for (int i = 0; i < 10; i ++) cout << count(b, i) - count(a - 1, i) << ' '; cout << endl; }
typedeflonglong LL; constint N = 12, M = 1 << N; int n, m; LL f[N][M]; vector<int> state[M]; bool st[M];
intmain() { while (cin >> n >> m, n || m) { //预处理st:能否合法放置的列 for (int i = 0; i < 1 << n; i ++) { int cnt = 0, is_vaild = true; for (int j = 0; j < n; j ++) { if ((i >> j) & 1) { if (cnt & 1) { is_vaild = false; break; } cnt = 0; } else cnt ++; } if (cnt & 1) is_vaild = false; st[i] = is_vaild; // cout << st[i] << " "; }
//预处理两列伸出不重叠冲突 for(int i = 0; i < 1 << n; i ++) { state[i].clear(); for (int j = 0; j < 1 << n; j ++) { if ((i & j) == 0 && st[i | j]) state[i].push_back(j); } // cout << state[i].size() << endl; }
memset(f, 0, sizeof f); //dp f[0][0] = 1; for (int i = 1; i <= m; i ++) for (int j = 0; j < 1 << n; j ++) for (auto k : state[j]) f[i][j] += f[i - 1][k];
constint N = 21, M = 1 << N; int n; int w[N][N]; int f[M][N];
intmain() { cin >> n; for (int i = 0; i < n; i ++) for (int j = 0; j < n; j ++) cin >> w[i][j];
memset(f, 0x3f, sizeof f); f[1][0] = 0; for (int i = 0; i < 1 << n; i ++) for (int j = 0; j < n; j ++) if (i >> j & 1) for (int k = 0; k < n; k ++) if (i - (1 << j) >> k & 1) f[i][j] = min(f[i][j], f[i - (1 << j)][k] + w[k][j]);
constint N = 310; int n, m; int h[N][N]; int f[N][N];
int dx[4] = {-1, 1, 0, 0}, dy[4] = {0, 0, -1, 1};
intdp(int x, int y) { int &v = f[x][y]; if (v != -1) return v;
v = 1; for (int i = 0; i < 4; i ++) { int a = x + dx[i], b = y + dy[i]; if (a >= 1 && a <= n && b >= 1 && b <= m && h[a][b] < h[x][y]) v = max(v, dp(a, b) + 1); }
return v; } intmain() { scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++) for (int j = 1; j <= m; j ++) scanf("%d", &h[i][j]);
memset(f, -1, sizeof f);
int res = -1; for (int i = 1; i <= n; i ++) for (int j = 1; j <= m; j ++) res = max(res, dp(i, j));